Benchmark project presented at a RadiUnce research meeting in Utrecht
Summary
Bastián González-Bustamante, together with Christopher Klamm, Tom Bellens, and Marta Koch, presented our benchmark project at a RadiUnce research meeting in Utrecht on 20 May 2026.
The presentation introduced the project’s broader goal of developing a transparent and reproducible framework for evaluating LLMs and fine-tuned models on multilingual policy agenda annotation in parliamentary speeches. It also provided an opportunity to discuss the benchmark in the context of the RadiUnce project, Politicians under Radical Uncertainty, which examines how politicians respond to different forms of uncertainty across political systems and reflects on lessons and guidelines when working with computational analysis of parliamentary speech.
Key highlight
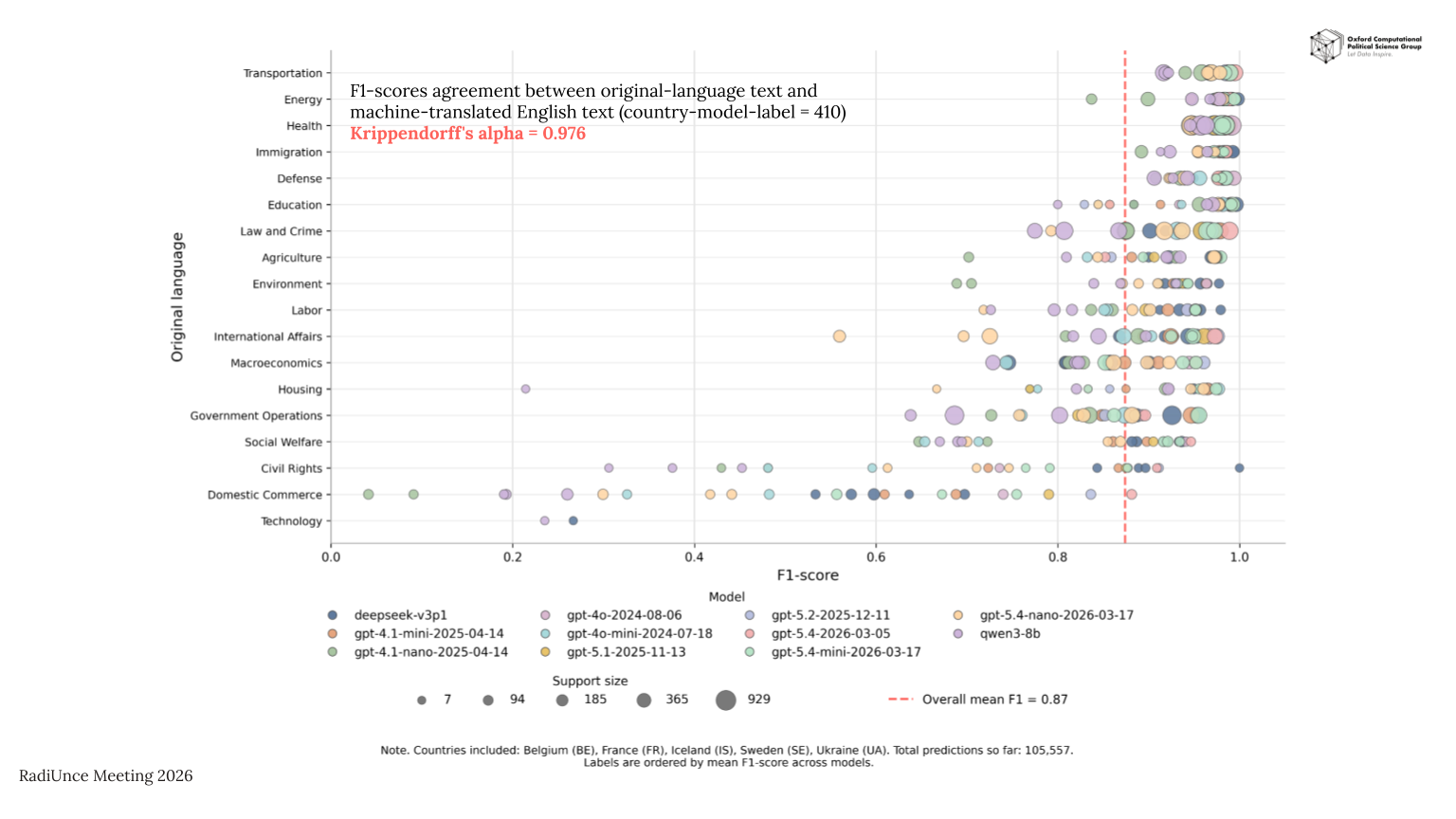
A central highlight of the presentation was a comparative plot showing our preliminary benchmark results for original-language speeches and their machine-translated English versions. The figure compares model performance across recent OpenAI GPT models, DeepSeek, and Qwen 3, providing an initial view of how these model families perform under the two input conditions.
The main takeaway so far is the very high level of agreement between classifications based on original-language speeches and those based on machine translations, with Krippendorff’s alpha = 0.976. This suggests that, at least in the current benchmark stage, machine translation preserves the information needed for highly consistent policy agenda classification across languages.