Christopher Klamm presented our benchmark project at APSA Workshop 2026
Summary
Christopher Klamm presented our project, Evaluating Large Language Models for Multilingual Policy Coding: A Transparent Benchmarking and Reporting Framework, at APSA Workshop 2026 on 15-16 April 2026.
The presentation introduced the benchmark’s core design and broader methodological motivation. It outlined how the project develops a transparent and reproducible framework for evaluating LLMs and fine-tuned models on multilingual policy agenda annotation in parliamentary speeches, with particular attention to cross-country comparability, reporting standards, and benchmark quality.
The workshop provided an opportunity to share the project with researchers working on computational methods across the political science research lifecycle and to discuss how benchmarking, validation, and reporting can be strengthened in the use of AI and machine learning for political science research.
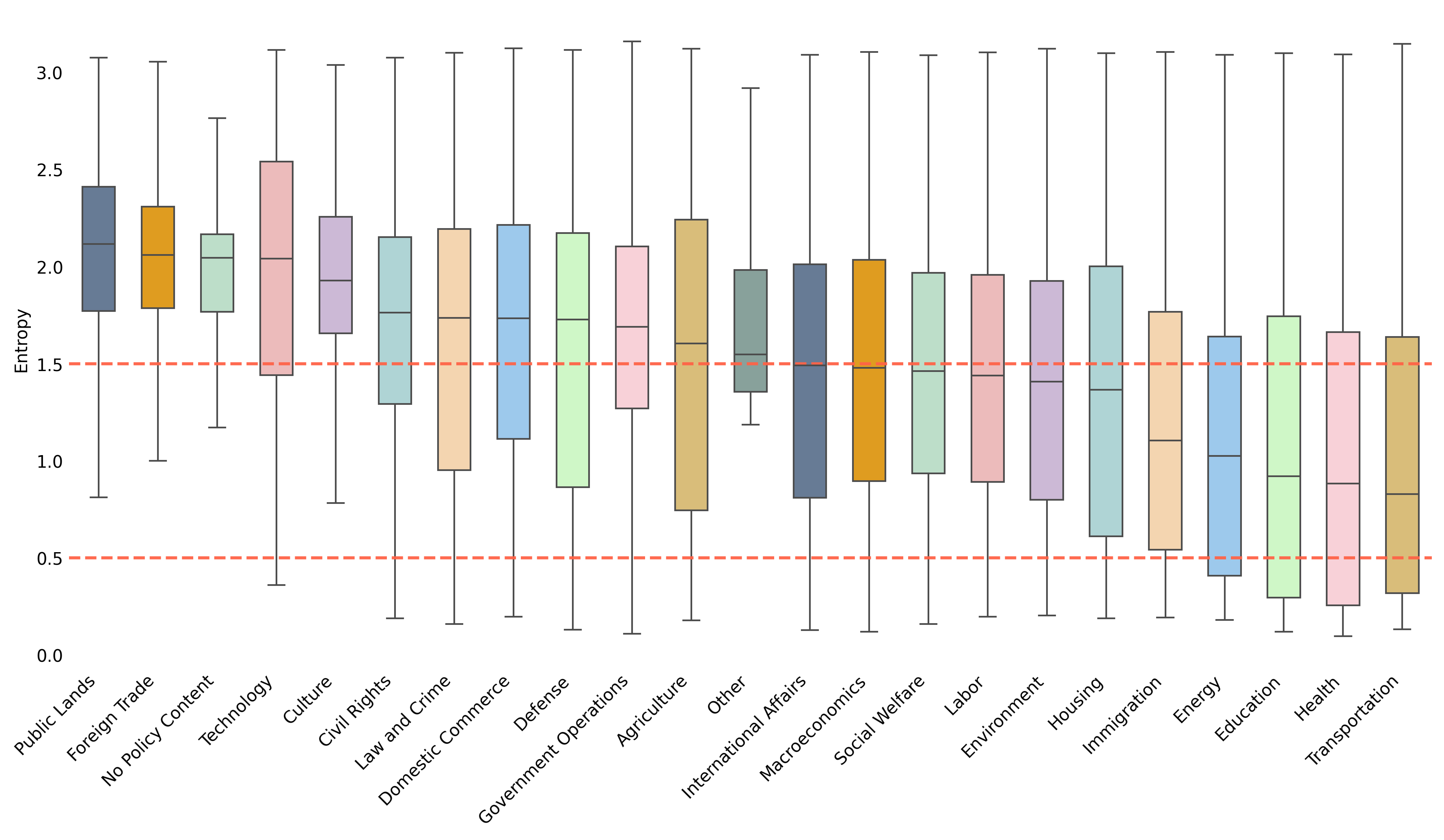
Key highlight
A central highlight of the presentation was a comparative plot showing entropy threshold values across all countries and major policy topics. The figure illustrates how uncertainty varies across labels and national contexts, and how entropy-based thresholds can be used to distinguish higher-confidence from more uncertain benchmark cases. This is an important component of the project’s benchmarking framework, as it helps make the quality and comparability of the labelled data more transparent.