Benchmark project presented at COMPTEXT 2026 in Birmingham
Summary
Bastián González-Bustamante, together with Tom Bellens, Christopher Klamm, and Marta Koch, presented our benchmark project at COMPTEXT 2026 in Birmingham on 23-25 April 2026.
The presentation introduced the project’s broader goal of developing a transparent and reproducible framework for evaluating LLMs and fine-tuned models on multilingual policy agenda annotation in parliamentary speeches. It outlined the benchmark’s comparative design, multilingual scope, and reporting logic, with a particular emphasis on cross-country comparability, validation, and reproducible evaluation practices.
Presenting the project at COMPTEXT provided an excellent opportunity to share our ongoing work with an interdisciplinary community of scholars working on the quantitative and computational analysis of text, image, audio, and video as data.
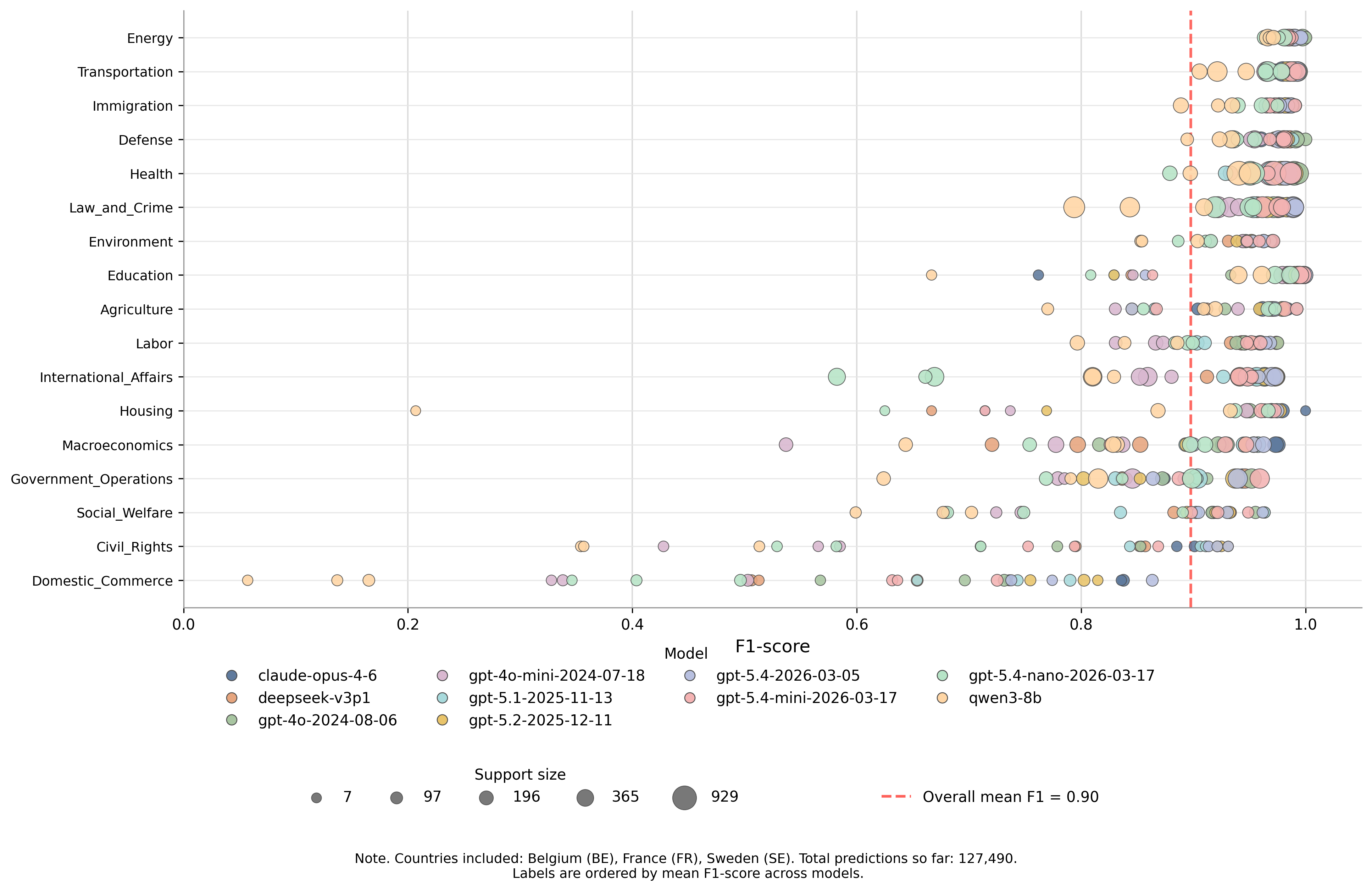
Key highlight
A central highlight of the presentation was a plot showing our preliminary benchmark results across a selection of leading LLMs. The figure compares model performance for recent OpenAI GPT models, Anthropic’s Claude Opus, DeepSeek 3.1, and Qwen 3, offering an initial view of how different model families perform on policy agenda annotation.
These preliminary results help illustrate the value of a common benchmark and reporting framework for assessing model performance across languages and task settings, while also identifying promising directions for further evaluation and refinement.
Additional team participation
Members of our team also contributed to COMPTEXT 2026 through several additional activities and presentations:
Workshop. From Appendix to Spotlight: Validation Standards in Text-as-Data Political Science, by Christopher Klamm, Bastián González-Bustamante, and Steffen Eckhard. This workshop is connected to a special issue that they are co-editing in PS: Political Science & Politics.
Roundtable participation. Bastián González-Bustamante participated in the roundtable AI for Sustainability: Promise, Paradox, and Responsibility, facilitated by Fabienne Lind. The session examined the paradox at the heart of AI-for-sustainability research: large-scale models are promoted as tools for addressing sustainability, yet training and running them generate substantial carbon emissions. Panellists discussed what computational social science can contribute beyond natural science applications, who governs these tools and in whose interest, and what professional responsibility researchers bear for the environmental costs of their work.
Presentation. Retrieval-augmented generation and multi-agent LLM orchestration for analysing the political economy of sustainability, by Bastián González-Bustamante and Natascha van der Zwan.
Presentation. Elite polarization in election campaigns under minority and majority governments, by Christopher Klamm, Flynn Schirott, Sven-Oliver Proksch, and Bruno de Castanho Silva.
Presentation. Making semi-structured interviews scalable: An experimental evaluation of AI conversational interviewing, by Alexander Wuttke, Matthias Aßenmacher, Christopher Klamm, Max M. Lang, Quirin Würschinger, and Frauke Kreuter.