Presentation at the OCPSG Research Cafe
Summary
We presented Benchmarking LLMs and Fine-Tuned Models for Multilingual Policy Agenda Annotation at the OCPSG Research Cafe on 27 March 2026.
The presentation introduced the project’s main motivation, benchmark design, and multilingual scope. We outlined how the project develops a shared framework for evaluating large language models and fine-tuned models on policy agenda annotation in parliamentary speeches, with an emphasis on reproducibility, cross-country comparability, and transparent evaluation.
We also discussed the broader benchmark architecture, including its comparative orientation, evaluation workflow, and the role of standardised inputs and outputs in enabling systematic comparison across models.
The Research Cafe provided an opportunity to share the project with other participants in the Oxford Computational Political Science Group’s Research Programme and to situate the benchmark alongside a wider set of ongoing computational social science projects.
Key highlight
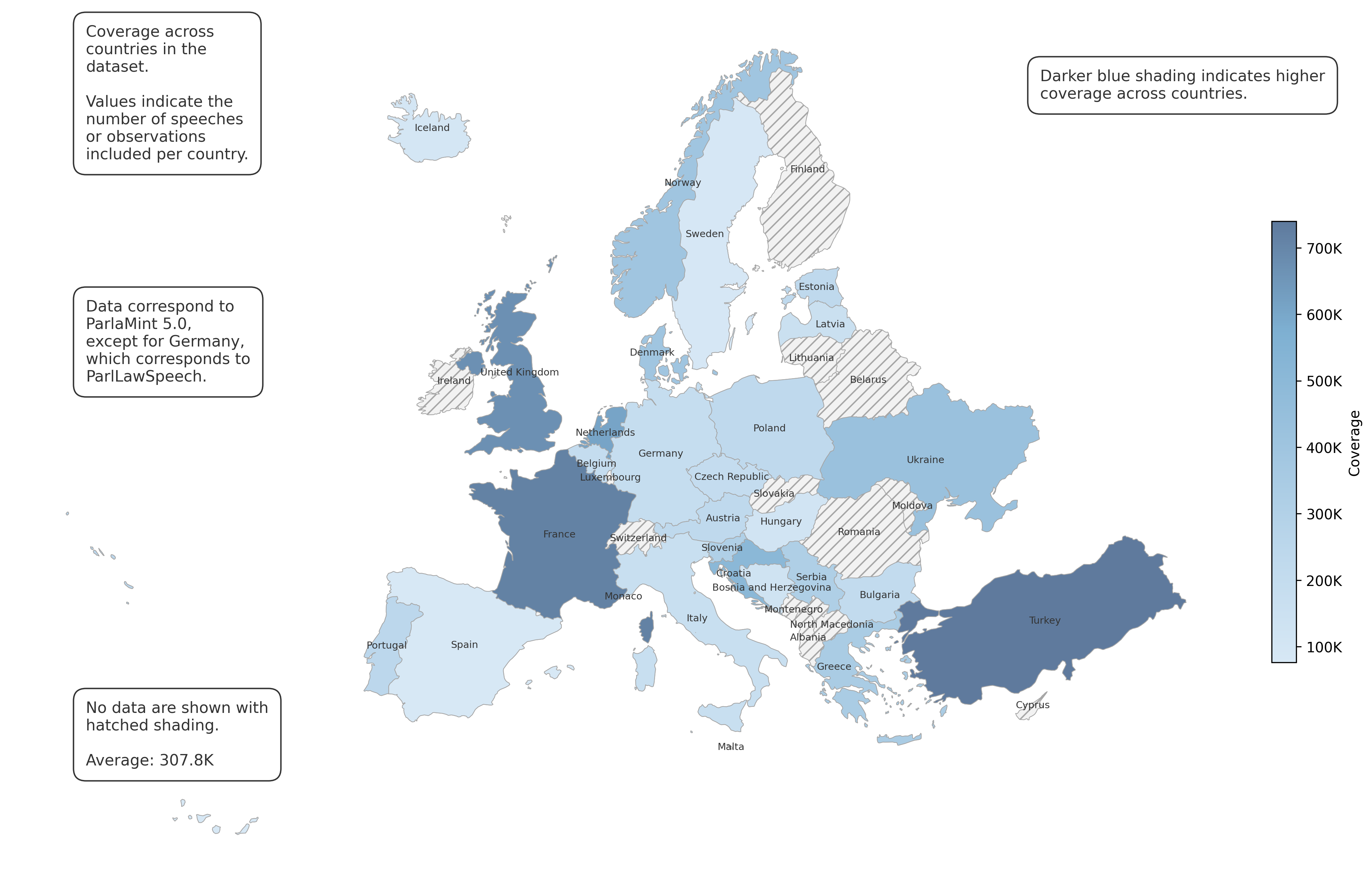
The project pipeline begins with parliamentary speeches represented in two textual channels: original-language speeches and their English machine translations. The corpus is drawn primarily from the ParlaMint 5.0 dataset and supplemented for Germany with the ParlLawSpeech dataset.
On this basis, we generate three baseline classifier outputs for each speech using BERT models: one label from ParlaCAP, one label from CAP Babel Machine applied mainly to machine-translated speeches, and one label from CAP Babel Machine applied generally to original-language speeches.
A central descriptive result is the project’s broad cross-national data coverage, with an average of more than 307,000 speeches per case.